
6. Full-stack GraphQL application using GRAND stack

I am a software developer who loves learning and building new technologies and projects from the scratch !
This is the 6th blog as part of the series Full Stack: Remastering Master Data Management into graph like data. Hope you enjoy the series and find it useful !!
Introduction
We often need a data-fetching API powerful enough to describe all of your data in a structured format. But in order to build that you might need a huge infrastructure and documentation to let people know the number of ways the data can be queried through various API URL's. So we might require an API framework, powerful yet simple enough to be easy to learn and use by any product developers.
Here comes GraphQL, which is a query language for your API, and a server-side runtime for executing queries by using a type system you define for your data. GraphQL isn't tied to any specific database or storage engine and is instead backed by your existing code and data.
REST vs GraphQL
- REST is an architectural style whereas GraphQL is a framework/query language.
- REST supports various HTTP methods like GET/POST/PUT/PATCH/DELETE whereas GraphQL only supports POST call.
- In REST, URLs change as per the query or requirement whereas in GraphQL, URL is constant and payload changes as per the requirement in the response structure.
- REST does over-fetching/under-fetching of data/information whereas GraphQL does Server Side Filtering often known as Resolvers.
When to use GraphQL
Lets take a use-case, suppose you want to create a movie ticket-booking application. You might have to support multiple clients which can initiate the calls to fetch data, then GraphQL is the best candidate to integrate with those client applications. But within the eco-system, there might be multiple services which would like to integrate with this data, then REST API would be the most suitable choice.
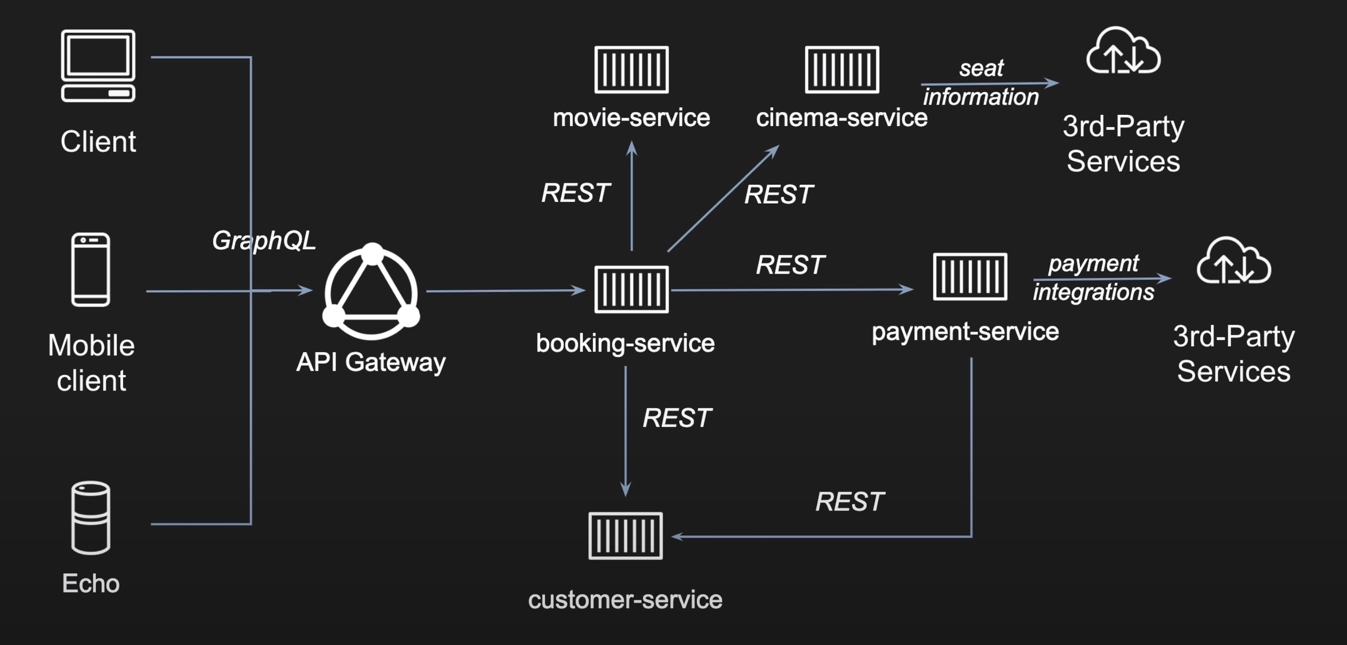
Having said that, lets see how we can write a simple GraphQL application. So lets continue using our data and build this application. You have already seen how we have ingested our data into Neo4j. We will now use GRAND stack to continue rest of the client side integration part.
GRAND stack
GRAND stack is a combination of technologies that work together to enable developers to build data intensive full stack applications. The components of GRAND stack are:
- GraphQL - A new paradigm for building APIs, GraphQL is a way of describing data and enabling clients to query it.
- React - A JavaScript library for building component based reusable user interfaces.
- Apollo - A suite of tools that work together to create great GraphQL workflows.
- Neo4j - The native graph database that allows you to model, store, and query your data the same way you think about it: as a graph.
Neo4j-Apollo Data Graph Platform
Apollo is the industry-standard GraphQL implementation, providing the data graph layer that connects modern apps to the cloud. The Apollo platform helps you build, query, and manage a data graph: a unified data layer that enables applications to interact with data from any combination of connected data stores and external APIs.
A data graph sits between application clients and back-end services, facilitating the flow of data between them:

Get Started
We can easily install and start a GRAND stack by executing:
npx create-grandstack-app grand-data-lake-frontend
This installs both API and React starter with all its dependencies.
A GraphQL service is created by defining types and fields on those types, then providing functions for each field on each type. For example, a GraphQL service that tells us User and various relations with various entities might look something like the file below:
schema.graphql:
type User {
id: String!
employeeId: String
firstName: String
middleName: String
lastName: String
photo: String
employeeTitle: String
employeeOrganization: String
employeeStatus: String
email: String
location: String
mobilephone: String
homePhone: String
officePhone: String
startTime: Int
endTime: Int
notes: String
parent: [User] @relation(name: "PersonaReportsToPersona", direction: OUT)
children: [User] @relation(name: "PersonaReportsToPersona", direction: IN)
}
You can create an executable GraphQL schema object from GraphQL type definitions including auto-generated queries and mutations like below:
const typeDefs = fs
.readFileSync(
process.env.GRAPHQL_SCHEMA || path.join(__dirname, 'schema.graphql')
)
.toString('utf-8')
const schema = makeAugmentedSchema({
typeDefs,
config: {
query: true,
mutation: true,
},
});
Lets initiate a Neo4j instance by configuring below:
/* Create a full-text search index while initiating database */
const initializeDatabase = (driver) => {
const initCypher = `CALL db.index.fulltext.createNodeIndex("SearchString",["User"],["employeeOrganization", "employeeStatus", "firstName", "lastName", "location", "email", "middleName", "notes"], {analyzer: "url_or_email", eventually_consistent: "true"})`
const testCypher = `CALL db.indexes() YIELD name where name = "SearchString" RETURN name`
const checkIndex = (driver) => {
const session = driver.session()
return session
.writeTransaction((tx) => tx.run(testCypher))
.then()
.finally(() => session.close())
};
const executeQuery = (driver) => {
const session = driver.session()
return session
.writeTransaction((tx) => {
tx.run(initCypher)
})
.then()
.finally(() => session.close())
};
checkIndex(driver).catch((error) => {
console.error(error.message)
executeQuery(driver).catch((error) => {
console.error(
'Database indexing and initialization failed to complete!!\n',
error.message
)
})
})
};
const driver = neo4j.driver(
process.env.NEO4J_URI,
neo4j.auth.basic(process.env.NEO4J_USER, process.env.NEO4J_PASSWORD),
{
encrypted: process.env.NEO4J_ENCRYPTED ? 'ENCRYPTION_ON' : 'ENCRYPTION_OFF',
}
);
const init = async (driver) => {
await initializeDatabase(driver)
};
init(driver);
That's it !! Now you can start the application by calling:
npm run start
which will start the GraphQL playground in http://localhost:4001/graphql. You can write a simple query like below:
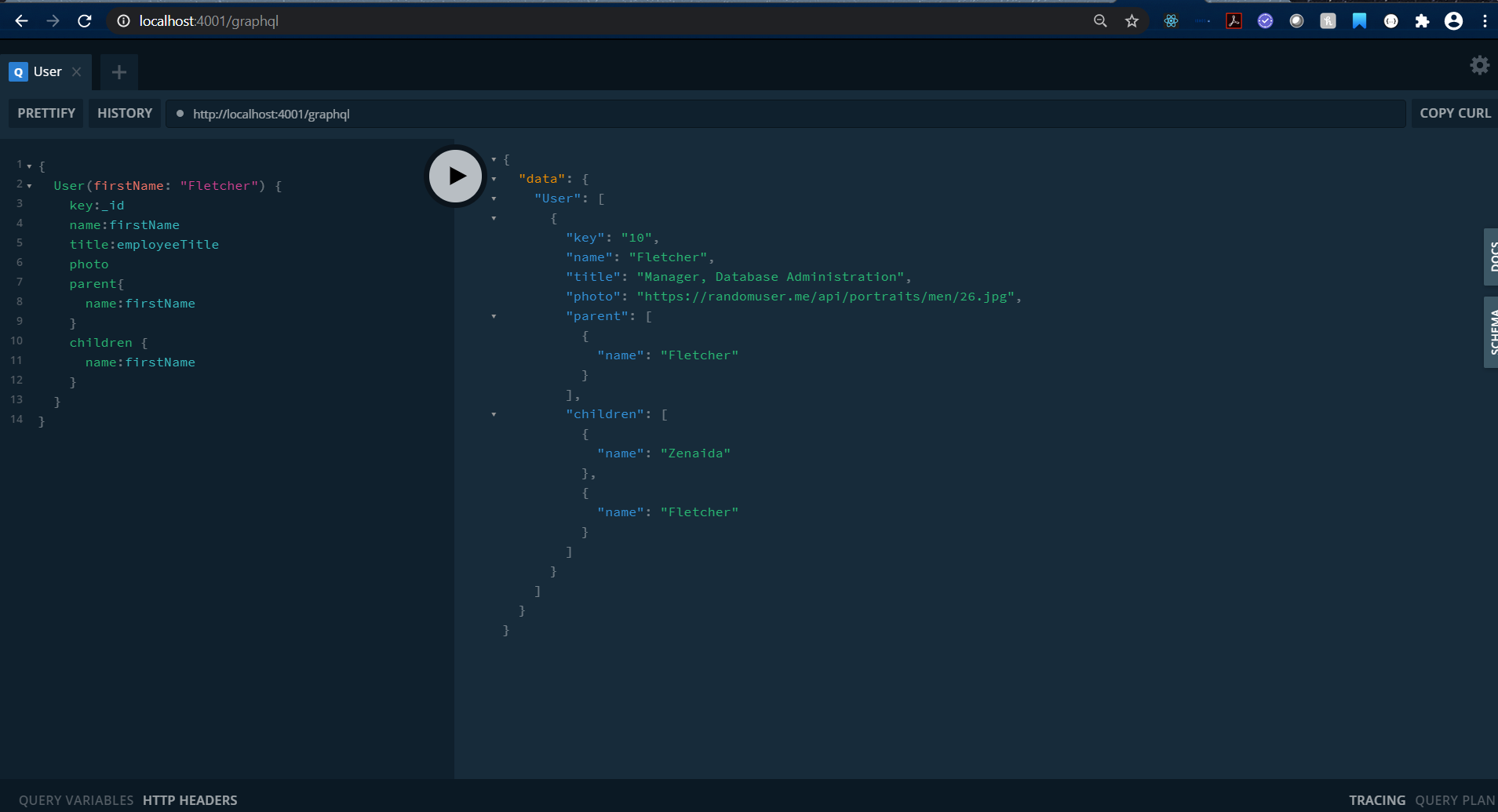
Now once we have the data, we can also write some React code to render those data to form graph data.
React UI with hierarchical data
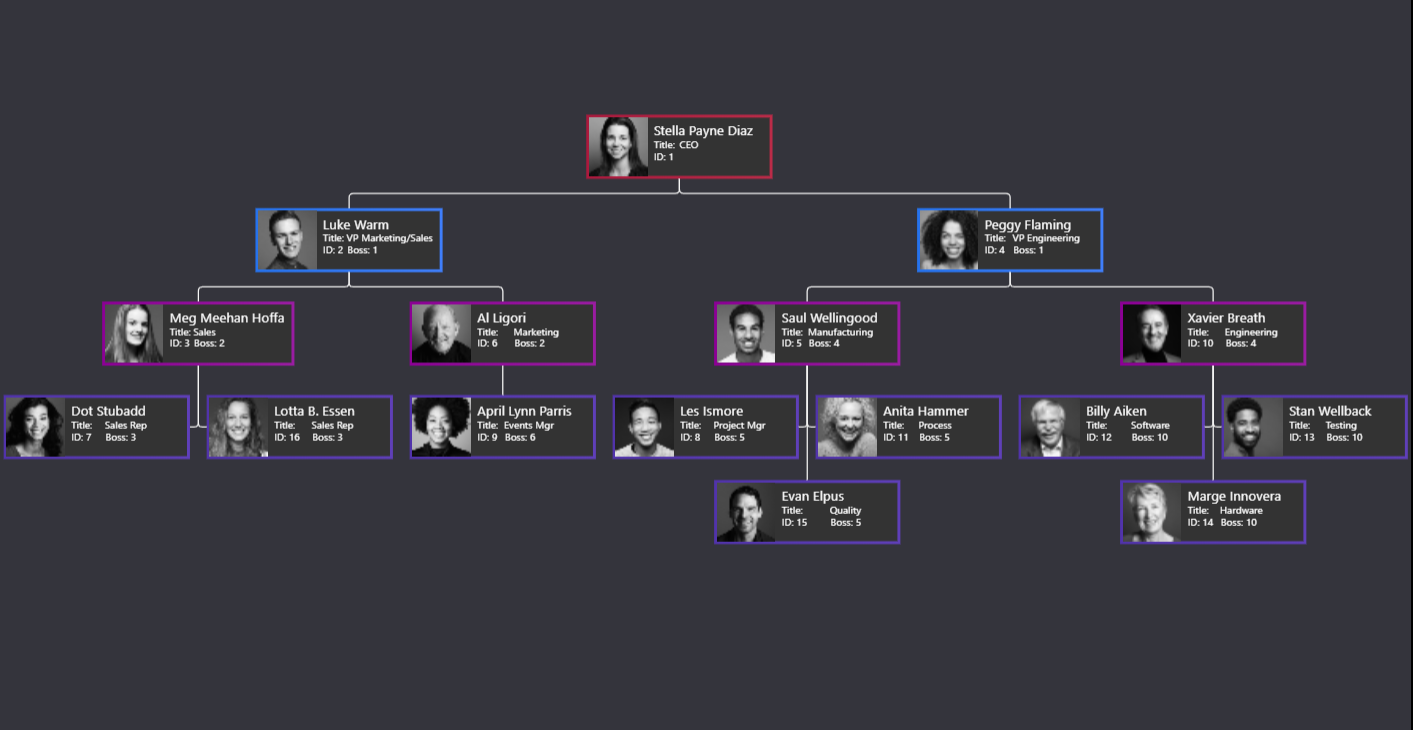
A typical use-case to create a hierarchical Graph data with User information in an organization would be to build a typical Organization chart based upon the queried user info. There are many D3 visualizations but most of them look out for some basic information to build those like:
- Nodes
- Vertices
- Edges
- Links
- Level
Once you provide those information, you can build an Organizational chart like this:
Source Code
Lets try to add some more Entities for schema. You can find the source code in:




