
Indexed Full-Text searching made easy

I am a software developer who loves learning and building new technologies and projects from the scratch !
Introduction
Well we all might have come across the word search in our day-to-day life. But ever thought how difficult and complex would be to create a search engine?
I have seen and been part of many projects where they either use a large cluster of ELK(ElasticSearch-Logstash-Kibana) stack or Solr indexing or try to write their own optimized aggregated query over any existing SQL engine. After working in those projects I realized its too complex to maintain and improve performance or efficiency with the ever urging needs of the websites to load huge data faster.
While reading more about various efficient data structures involved in searching mechanisms, I got to realize that a basic Trie data structure and a basic TF-IDF algorithm might help in achieving an efficient low cost search engine. So when I was going through various datastores, I came across Redisearch which was pretty new to the market.
By seeing their benchmarks and comparison with elastic search, I was pretty impressed and couldn't stop myself from trying it out.
Installing Redisearch
If you are running docker, redisearch can be easily installed and run using the following command:
docker run -p 6379:6379 redislabs/redisearch:latest
Using JRedisearch
After installing Redisearch, you might need a library to interact through various APIs. If you are writing a Java application, you can use JRedisearch library to create connection and write your query.
A sample snippet code to create a client connection and execute a query would be:
import io.redisearch.client.Client;
import io.redisearch.Document;
import io.redisearch.SearchResult;
import io.redisearch.Query;
import io.redisearch.Schema;
Client client = new Client("test", "localhost", 6379);
Schema sc = new Schema()
.addTextField("title", 5.0)
.addTextField("body", 1.0)
.addNumericField("price");
client.createIndex(sc, Client.IndexOptions.Default());
Map<String, Object> fields = new HashMap<>();
fields.put("title", "hello world");
fields.put("state", "NY");
fields.put("body", "lorem ipsum");
fields.put("price", 1337);
client.addDocument("doc1", fields);
// Creating a complex query
Query q = new Query("hello world")
.addFilter(new Query.NumericFilter("price", 0, 1000))
.limit(0,5);
// actual search
SearchResult res = client.search(q);
// aggregation query
AggregationBuilder r = new AggregationBuilder("hello")
.apply("@price/1000", "k")
.groupBy("@state", Reducers.avg("@k").as("avgprice"))
.filter("@avgprice>=2")
.sortBy(10, SortedField.asc("@state"));
AggregationResult res = client.aggregate(r);
User Profile App
I used this library and tried to write a small Spring Boot application using which I indexed around 100000 users with around 10 columns each. I could benchmark and see that the code takes around 54 seconds to index all the documents and around 52 seconds to create auto-complete suggestions.
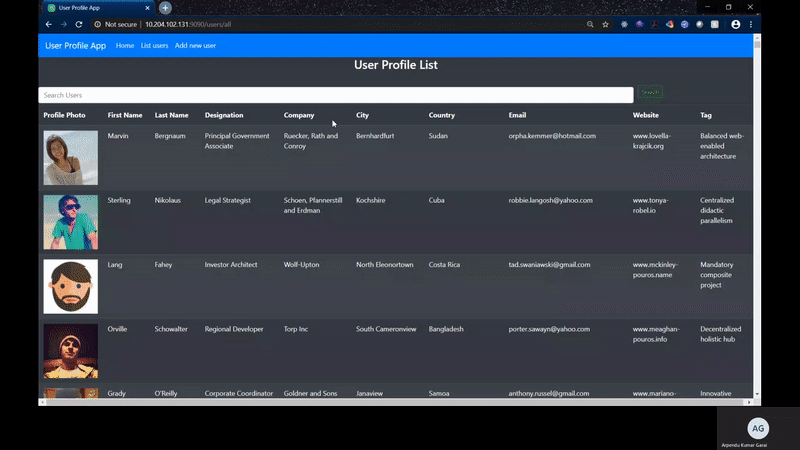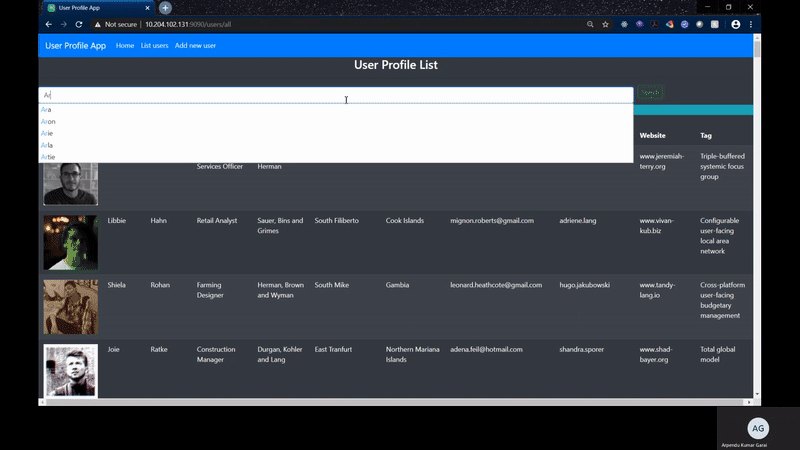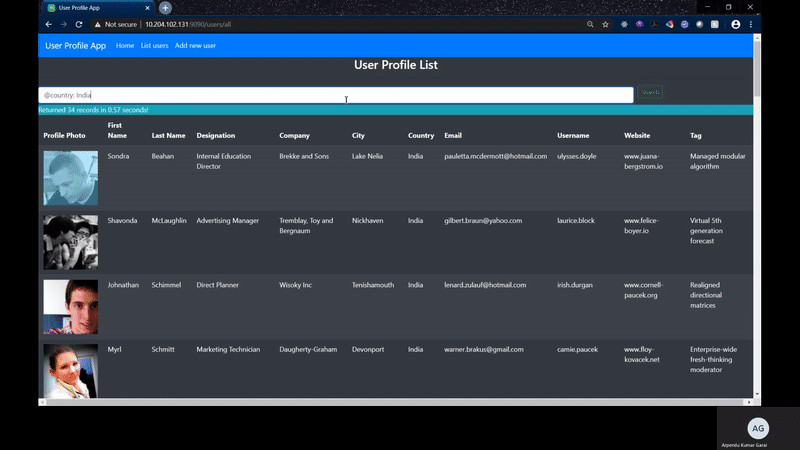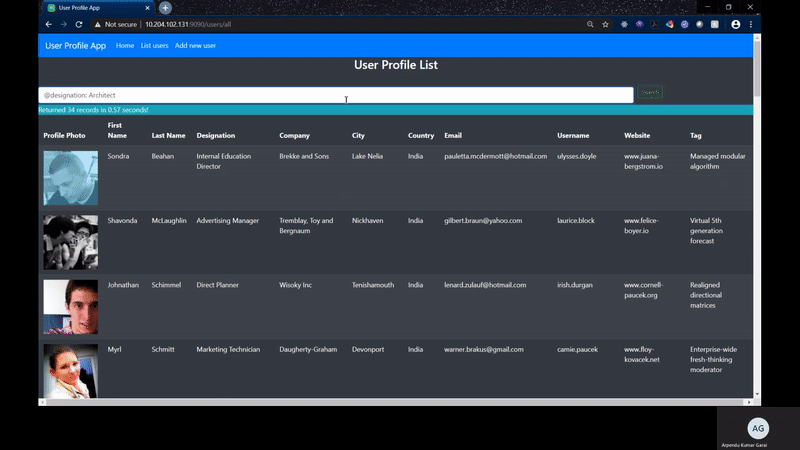
Now when I search the records with the auto-complete feature, it resolves in less than a second to 3 seconds time which is an ideal benchmark for any search page showing real time data. It also allows to do a fuzzy search which was cool as well.
I have created two Rest APIs for executing the search based on the usage of the above library.
- /users/api/search POST call with payload returning "term"
public SearchResult search(String term) {
Query query = new Query(term).limit(0, 500).setWithScores();
return getClient().search(query);
}
- /users/api/partial?partialTerm=Arpendu
public List<Suggestion> getSuggestions(String partial) {
List<Suggestion> suggestions = getClient().getSuggestion(partial, SuggestionOptions.builder().fuzzy().build());
suggestions.stream().map(suggestion -> suggestion.getString()).collect(Collectors.toList());
return suggestions;
}
Technologies
This app is written from the scratch using following technologies:
Source Code
You can find the source code in https://github.com/arpendu11/user-profile-app
See it in action
Cover Photo credit
Cover Photo by Edho Pratama on Unsplash.




