




This is the 4th blog as part of the series Full Stack: Remastering Master Data Management into graph like data. Hope you enjoy the series and find it useful !!
Introduction
In the world of Big data and with so many tools available in the market, its pretty hard to choose the best tool for fast and enormous data processing. But one common element in all the architecture would be Apache Spark. Once you start using this, you would love it and get amazed by its capabilities. Lets talk about one of the most used library in this segment.
Spark Streaming is an extension to Core Apache Spark that enables scalable, high-throughput, fault-tolerant stream processing of live data streams. Source data streams can be any of the following as described in the below image and more.

Under the covers, Spark Streaming operates with a micro-batch architecture. This means that periodically, (every X number of seconds) Spark Streaming will trigger a job to be run on the Spark Engine. During this time, Spark will pull messages from some source, process the data using the Directed Acyclic Graph (DAG) you defined, and save the data to the location you specify as a Sink.
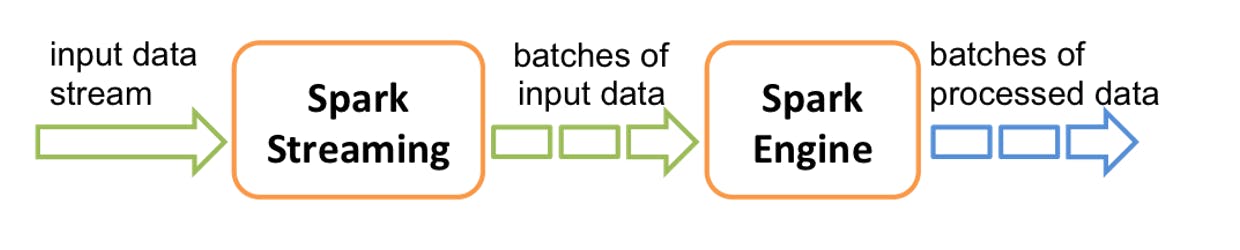
In this blog, I am going to implement a basic Java example on Spark Structured Streaming & Kafka Integration and orchestrate the fault-tolerant job using a continuous loop Multi-threading process.
Dependencies
First things first, lets add the required dependencies:
<properties>
<scala.version>2.12</scala.version>
<spark.version>2.4.3</spark.version>
</properties>
<dependencyManagement>
<dependencies>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_${scala.version}</artifactId>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_${scala.version}</artifactId>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql-kafka-0-10_${scala.version}</artifactId>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-hdfs</artifactId>
<version>2.2.0</version>
</dependency>
</dependencies>
</dependencyManagement>
Create Spark Session
Now, we have to import the necessary classes and create a local SparkSession, the starting point of all functionalities in Spark.
SparkConf conf = new SparkConf()
.setAppName("Reactive Streaming of User to Kafka Data Ingestion Spark Job")
.setMaster("local[3]");
SparkSession kafkaSession = SparkSession
.builder()
.config(conf)
.getOrCreate();
kafkaSession.sparkContext().setLocalProperty("spark.scheduler.mode", "FAIR"); //Spark assigns tasks between jobs in a “round robin” fashion
kafkaSession.sparkContext().setLocalProperty("spark.scheduler.pool", "pool1"); //grouping jobs into pools
kafkaSession.sparkContext().setLocalProperty("spark.streaming.stopGracefullyOnShutdown","true"); //Spark shuts down the StreamingContext gracefully on JVM shutdown rather than immediately
Create Dataset and Dataframe
A Dataset is a distributed collection of data. It provides the benefits of RDDs (strong typing, ability to use powerful lambda functions) with the benefits of Spark SQL’s optimized execution engine. A Dataset can be constructed from JVM objects and then manipulated using functional transformations (map, flatMap, filter, etc.).
A DataFrame is a Dataset organized into named columns. It is conceptually equivalent to a table in a relational database or a data frame in R/Python, but with richer optimizations under the hood. DataFrames can be constructed from a wide array of sources such as: structured data files, tables in Hive, external databases, or existing RDDs. In Scala and Java, a DataFrame is represented by a Dataset of Rows. Users need to use Dataset<Row> to represent a DataFrame.
Dataset<Row> users = kafkaSession.readStream()
.format("kafka")
.option("kafka.bootstrap.servers", "127.0.0.1:9092")
.option("subscribe", "user")
.option("startingOffsets", "earliest")
.option("failOnDataLoss", "false")
.load();
Dataset<User> usersDS = users.selectExpr("CAST(value AS STRING) as message")
.select(functions.from_json(functions.col("message"), User.getStructType()).as("json"))
.select("json.*")
.as(Encoders.bean(User.class));
Now if you want to print the data in a console, you can use:
users.show();
Once you get this dataframe, you can apply various transformations or aggregations. Spark itself has various Built-in functions for aggregation or you can use its User-Defined Aggregate functionality. You can also compute some data for machine learning processes as well.
But here we want to simply stream the data continuously to another Kafka topic. We will use the concept of Streaming Query.
Streaming Query
The StreamingQuery object created when a query is started can be used to monitor and manage the query. You can start any number of queries in a single SparkSession. They will all be running concurrently sharing the cluster resources. You can use sparkSession.streams() to get the StreamingQueryManager that can be used to manage the currently active queries.
StreamingQuery query = usersDS
.selectExpr("CAST(startTime AS STRING) AS key", "to_json(struct(*)) AS value")
.writeStream()
.format("kafka")
.option("kafka.bootstrap.servers", "127.0.0.1:9092")
.option("topic", "user-delta")
.option("startingOffsets", "latest")
.option("endingOffsets", "latest")
.option("failOnDataLoss", "false")
.option("checkpointLocation", "./etl-from-json/user") // Recovers from failures with checkpointing
.outputMode("update") // create/update based on availability
.start();
query.awaitTermination(300000);
kafkaSession.stop();
If you want to run the query in continuous mode, you can use additional option:
.trigger(Trigger.Continuous("1 second"))
A checkpoint interval of 1 second means that the continuous processing engine will record the progress of the query every second. The resulting checkpoints are in a format compatible with the micro-batch engine, hence any query can be restarted with any trigger.
Orchestration of Spark Jobs using Multi-Threading
Now once we have defined all the above functionalities under some method in a class, we would like to orchestrate through code to run multiple jobs one after the another in a continuous loop. The main objective here is to define multiple Spark sessions and run those sessions one after the other in a sequential orchestrated manner.
So lets define a basic Thread executor with a Reentrant Lock and a condition:
public class ThreadExecutor {
private Lock lock = new ReentrantLock();
private Condition condition = lock.newCondition();
public void execute() throws InterruptedException {
ThreadName threadName = new ThreadName();
threadName.setName("UserIngestion");
SynchronizedWorker worker = new SynchronizedWorker();
ExecutorService executor = Executors.newCachedThreadPool();
executor.submit(worker.setThread("UserIngestion",lock, condition, "UserIngestion", "AccountIngestion", threadName));
executor.submit(worker.setThread("AccountIngestion",lock, condition, "AccountIngestion", "UserIngestion", threadName));
}
}
Also lets define a Synchronized Worker module:
public class SynchronizedWorker {
Logger logger = LoggerFactory.getLogger(SynchronizedWorker.class);
public Thread setThread(final String name,
final Lock lock,
final Condition condition,
String actualThreadName,
String nextThreadName,
ThreadName threadName) {
Thread thread = new Thread() {
@Override
public void run() {
while (true) {
lock.lock();
try {
while (threadName.getName() != actualThreadName) {
try {
condition.await();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
Thread.sleep(10000);
logger.info("=================================================================");
logger.info("Starting " + actualThreadName + " !!");
SparkJobService sparkJob = new SparkJobService();
switch (actualThreadName) {
case "UserIngestion":
sparkJob.startUserIngestion(); // This method contains the above Spark session logic for Users Entity
break;
case "AccountIngestion":
sparkJob.startAccountIngestion(); // This method contains the above Spark session logic for Account Entity
break;
default:
logger.info("Nothing to do... Taking some rest...!!");
Thread.sleep(120000);
logger.info("Wake up... Time to start working again...!!");
break;
}
threadName.setName(nextThreadName);
logger.info("=================================================================");
condition.signalAll();
} catch (InterruptedException | StreamingQueryException e) {
e.printStackTrace();
} finally {
lock.unlock();
}
}
}
};
return thread;
}
}
Then initiate the process in your main method using:
ThreadExecutor executor = new ThreadExecutor();
executor.execute();
That's it ! We have created a Spark Streaming Job pipeline to perform any kind of ETL process.
Source Code
Lets try to add more Spark jobs. You can find the source code in: